🚗 Predicting Injury Severity from Car Crash Conditions
Contributors: Oviya Adhan, Nory Arroyo, Caitlin Gainey, Christine Sako
Premise:
With the rise of automated driving technologies, understanding factors influencing crash injury severity proves vital for safer road integration. This work aims to support the development of predictive safety tools to inform future automated vehicle systems and infrastructure planning. Using California car crash data from the California Crash Reporting System (CCRS), available from the California Open Data Portal (1), our team built and trained varying machine learning models and compared their ability to predict injury severity levels based on vehicle, road, and involved party information, focusing on improving the detection of fatal outcomes.
Methodology:
Using Python’s Scikit-learn and TensorFlow libraries, we compared multiple supervised learning algorithms (Multiclass Regression, Neural Network, Random Forest, and XGBoost) to predict crash injury severity. The process included:
Data Cleaning & Pre-Processing – 2024 data used for training and validation datasets, while 2025 data served as the test data. One-hot encoding was applied to the various categorical input variables to better serve the models.
Exploratory Data Visualization – Conducted EDA on categorical and continuous crash features; visualized class imbalance and feature distributions to guide preprocessing.
Model Development – Developed a baseline Multiclass Logistic Regression model and extended the analysis with optimized Neural Network, Random Forest, and XGBoost models:
Neural Network: Tuned with ablation study on activation/optimizer pairs and various hidden layer configurations. Addressed class imbalance using balanced class weights. Optimal model = ReLU, SGD, one hidden layer (128 units).
Random Forest: Split data with stratified k-fold cross-validation to ensure robustness. Tuned with randomized grid search over tree depth, estimator count, splits/leaves, and optional PCA dimensionality reduction. Addressed class imbalance using SMOTE (synthetic oversampling). Optimal model = no PCA, 3-fold stratified cross validation, 190 trees, 5 splits, maximum tree depth of 30.
XGBoost: Tuned through randomized grid search over learning rate, estimators, L1/L2 terms. Addressed class imbalance using balanced class weights. Optimal model = 200 trees, learning rate 0.1, L1=0.1, L2=1.3.
Model Evaluation – Primary metrics included macro-averaged F1-score (with special attention to the minority ‘Fatal’ class) and accuracy to track generalization.
Tools: Python (Pandas, NumPy, SciKit Learn, TensorFlow, Matplotlib, Altair)
Results:
Logistic regression provided an interpretable baseline, while tree-based models captured feature interactions and the neural net learned nonlinear patterns. Due to significant class imbalance, we evaluated models using both accuracy and macro-averaged F1 scores, with particular focus on improving the F1 score for the Fatal injury class to better detect life-critical outcomes. The key metrics were measured as follows:
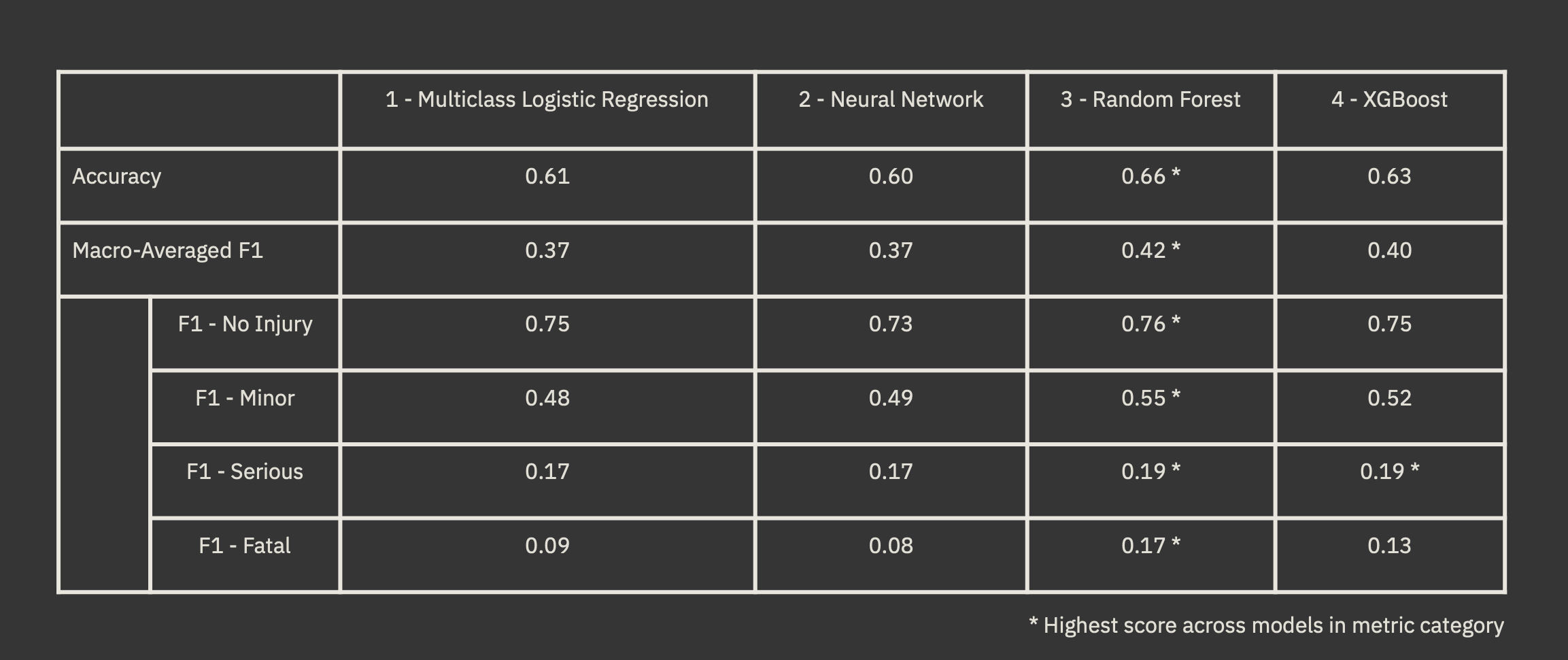
The Random Forest model performed best across all metrics, demonstrating its strength in handling complex, imbalanced data, followed by XGBoost, Multiclass Logistic Regression, then Neural Network. This result resembles past work done by Ahmed et al. (2023) (2) which found Random Forest to be the highest performing model in predicting road accidents in New Zealand as well as research done by Ardakani et al. (2023) (3) predicting car accidents in the United Kingdom citing the Random Forest classifier as the top performing model over Decision Trees and Multiclass Logistic Regression. Overall, all models provided moderately good results with the noise in the input data and the major class imbalance proving to be hindrances to reaching production-level performance.
Limitations & Future Work:
Considering the challenges faced with class imbalance between output classes, noisiness of our input data, and limited timeline, future work could include:
Reframing the problem as binary classification (`Serious`/`Fatal` vs. `Minor`/`No Injury`)
Prioritizing feature selection earlier to reduce overall noise
Leveraging greater computational resources to enhance model tuning, such as increasing the number of trees in ensemble models.
Check out the work behind this project at https://github.com/oadhan/Car-Crash-Injury-Severity-Prediction
Citations:
(1) California Department of Technology, California Department of Motor Vehicles, & California Highway Patrol. (2025). California crash report system (CCRS). Data.ca.gov. https://data.ca.gov/dataset/ccrs
(2) Ahmed, S., Hossain, M. A., Ray, S. K., Bhuiyan, M. M. I., & Sabuj, S. R. (2023). A study on road accident prediction and contributing factors using explainable machine learning models: Analysis and performance. Transportation Research Interdisciplinary Perspectives, 19, 100814. https://doi.org/10.1016/j.trip.2023.100814
(3) Pourroostaei Ardakani, S., Liang, X., Mengistu, K. T., So, R. S., Wei, X., He, B., & Cheshmehzangi, A. (2023). Road car accident prediction using a machine-learning-enabled data analysis. Sustainability, 15(7), 5939. https://doi.org/10.3390/su15075939